Материалы по тегу: intel xe
|
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
28.04.2023 [13:32], Сергей Карасёв
Серверное подразделение Intel несёт убытки, а его выручка падаетКорпорация Intel опубликовала неутешительные финансовые показатели по итогам I четверти 2023 финансового года, которая была закрыта 1 апреля. Суммарная выручка составила $11,7 млрд, что на 36 % меньше по сравнению с результатом годичной давности. Столь резкое падение отражает текущую макроэкономическую ситуацию и снижение спроса на оборудование. Чистые квартальные убытки, рассчитанные в соответствии с общепризнанными принципами бухгалтерского учёта (GAAP), зафиксированы на уровне $2,8 млрд — это худший показатель за всю историю Intel. Для сравнения: годом ранее корпорация получила чистую прибыль в размере $8,1 млрд. Убытки в пересчёте на одну ценную бумагу составили $0,66. 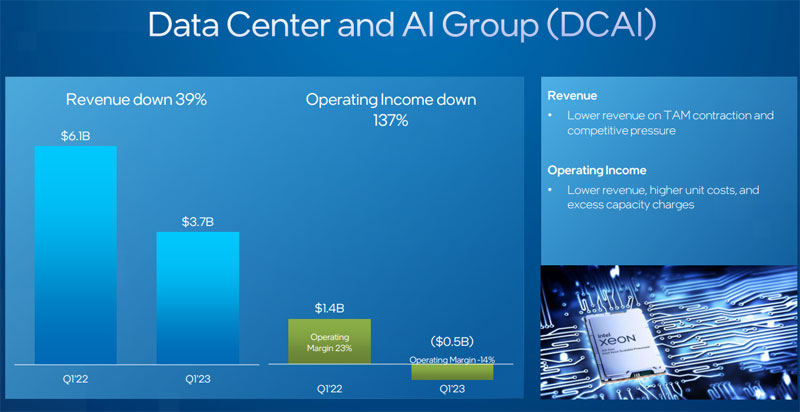
Источник изображений: Intel Выручка подразделения Datacenter and AI Group (DCAI), которое отвечает за решения для ЦОД и платформ ИИ, рухнула в годовом исчислении на 39 % — с $6,1 млрд до $3,7 млрд. Операционные убытки этой группы составили $518 млн, в то время как годом ранее была продемонстрирована операционная прибыль на уровне $1,4 млрд. Кроме того, Intel продала свой бизнес по производству серверов тайваньской MiTAC (Tyan).  Подразделение Network and Edge Group (NEX), специализирующееся на сетевых продуктах и периферийных вычислениях, по итогам I квартала 2023 года показало выручку около $1,5 млрд. Это на 30 % меньше прошлогоднего результата, равного $2,1 млрд. В этой группе также зафиксированы операционные убытки — около $300 млн. Годом ранее подразделение NEX продемонстрировало операционную прибыль в размере $416 млн. В прошлом году NEX лишилась направления коммутаторов. В отчёте также говорится, что выручка потребительской группы Client Computing Group (CCG), которая отвечает в том числе за решения для ПК, за год снизилась на 38 %, оказавшись на отметке $5,8 млрд.
25.04.2023 [20:01], Алексей Степин
Как Aurora, но поменьше: запущен тренировочный суперкомпьютер Sunspot на чипах Intel MaxОдин из самых масштабных проектов в области высокопроизводительных вычислений (HPC), 2-Эфлопс суперкомпьютер Aurora, который планирует вскоре ввести в строй Аргоннская национальная лаборатория (ANL), получил ещё одну тестовую платформу. Новый мини-кластер Sunspot, включающий в себя две стойки будущей машины, является прекрасным полигоном для отладки ПО. Aurora будет состоять из более чем 10 тыс. вычислительных узлов, а Sunspot включает в себя 128 узлов, каждый из которых, впрочем, имеет весьма серьёзную конфигурацию. На борту такой узел несёт пару процессоров Intel Xeon Max (Sapphire Rapids + 64 Гбайт HBM2e), а также шесть ускорителей Intel Max Series (Ponte Vecchio). Sunspot использует в качестве интерконнекта фирменную сеть HPE/Cray Slingshot последнего поколения. 
Источник: Argonne Leadership Computing Facility Как считает глава Argonne Leadership Computing Facility (ALCF), полная идентичность архитектур позволит разработчикам оптимизировать код для максимального использования всех возможностей Sapphire Rapids и Ponte Vecchio. Ранее тестовыми платформами служили кластеры Iris, Arcticus, Florentia самой Аргоннской лаборатории, а также Borealis, принадлежащий Intel. Система Sunspot была запущена ещё в декабре, с тех пор к ней получили доступ более 180 исследователей из 20 команд разработчиков в рамках программ Aurora Early Science Program (ESP) и Exascale Computing Project (ECP). 
Процесс сборки Aurora идёт полным ходом Отмечается, что достигнутые на «железе» Intel Max результаты внушают оптимизм. В ряде научно-технических задач прирост производительности от перехода на ускорители Intel составил от 20 до 70 %, а в разрабатываемом аргоннцами Hardware/Hybrid Accelerated Cosmology Code выигрыш достиг 2,6 раз. Ожидается, что дальнейшая более тонкая оптимизация позволит улучшить результаты. Интересно, что даже после запуска Aurora система Sunspot демонтирована не будет, а станет, как и все предыдущие тестовые платформы ALCF, общедоступным «полигоном для новичков».
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 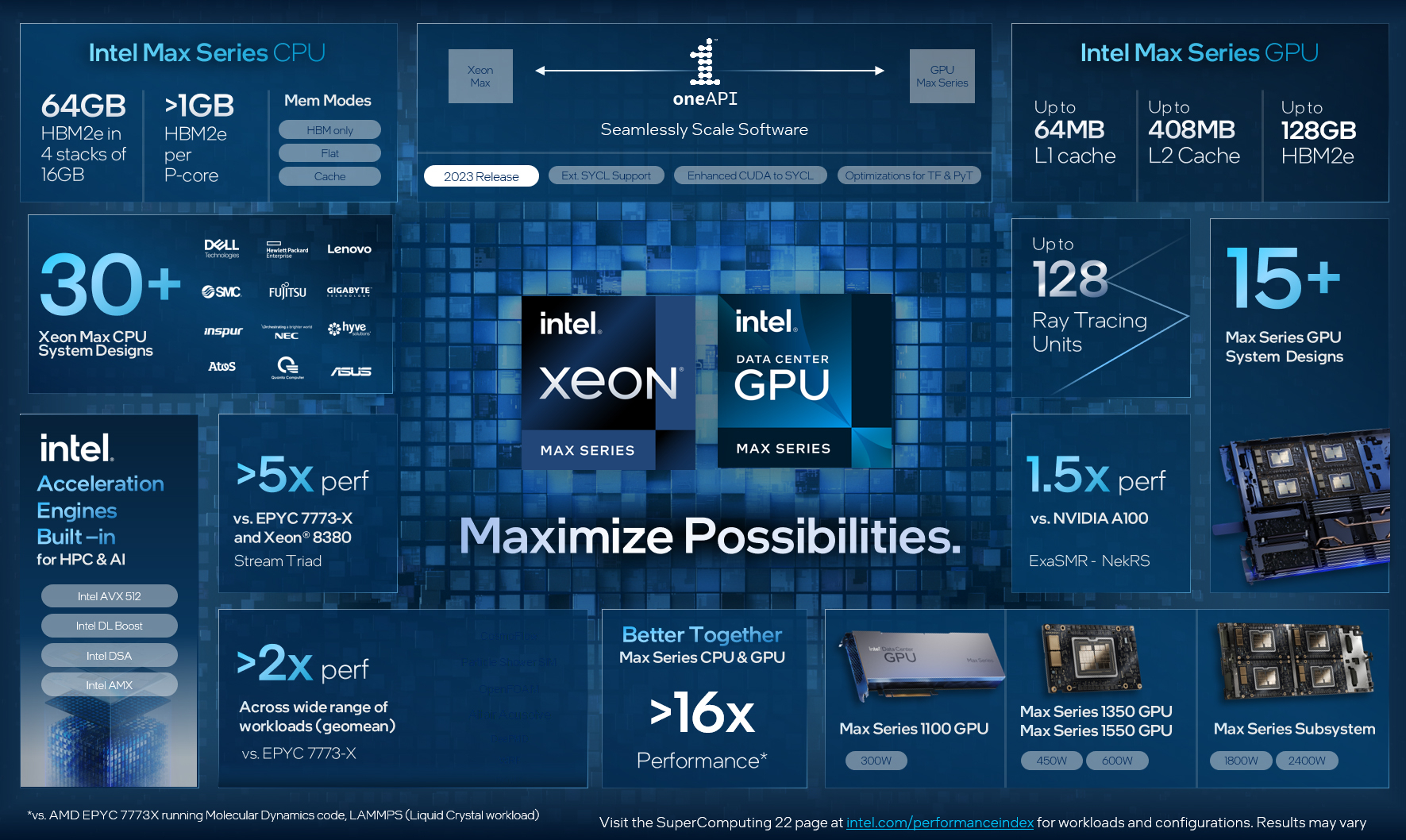
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 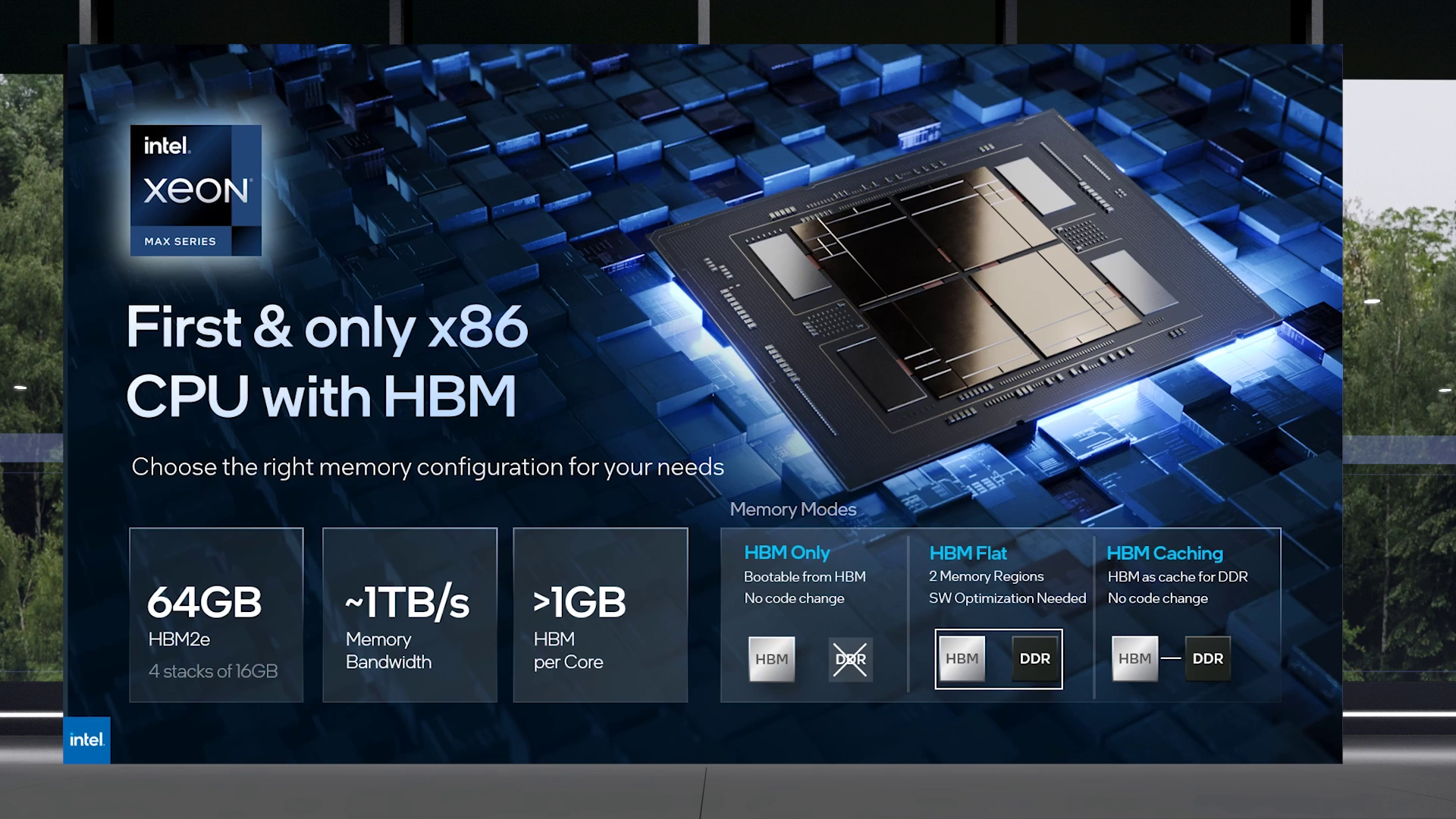 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 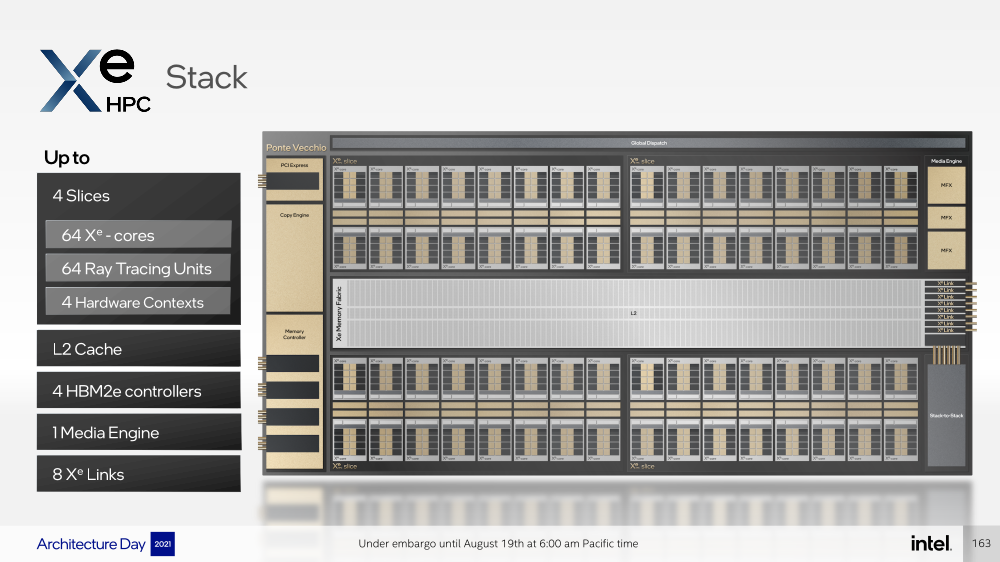 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 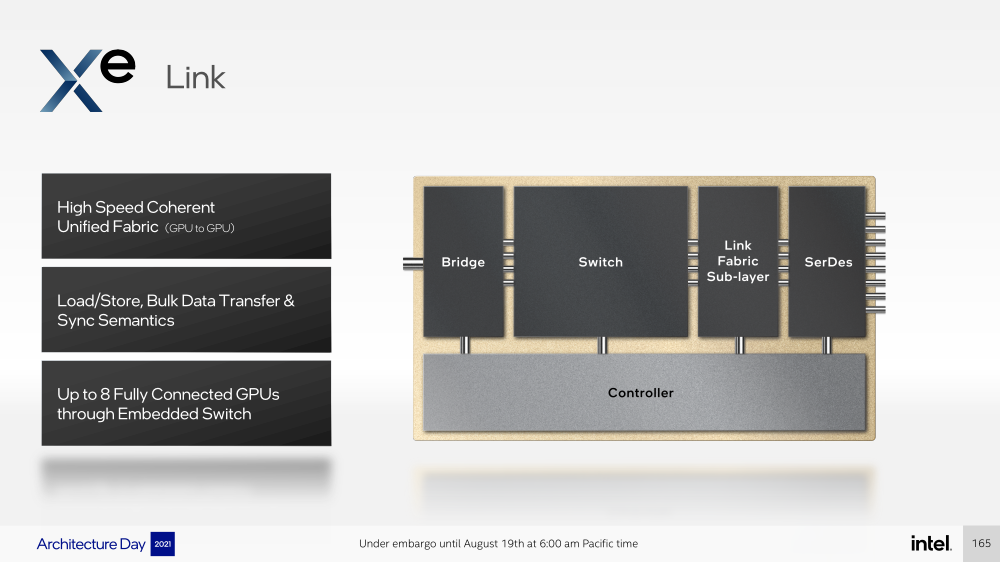  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 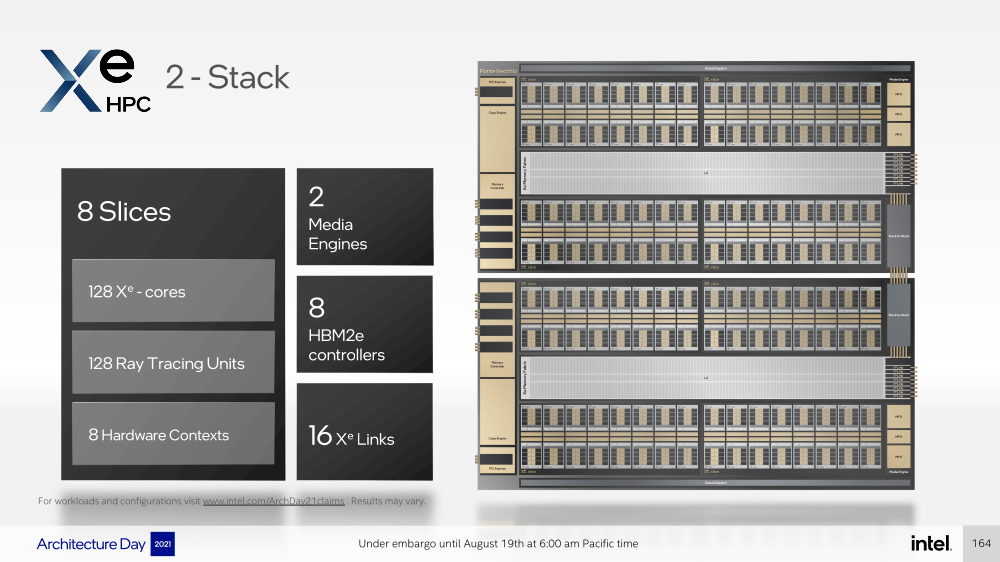 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA. |
|


